The UK government defines AI Assurance as "the process of measuring, evaluating, and communicating the trustworthiness of AI systems." The market is worth over one billion pounds. PwC, EY, KPMG, and Deloitte all have offerings. Over 524 companies in the UK alone work on some form of it.
And yet, if you ask a developer what AI Assurance actually means for their workflow, you'll get a blank stare. If you ask a compliance officer how to implement it without hiring a Big 4 consultancy, you'll get a longer blank stare.
The problem isn't that AI Assurance is vague. It's that most definitions describe an outcome — trustworthy AI — without describing the mechanism. It's like defining DevOps as "delivering software reliably" without mentioning CI/CD, infrastructure-as-code, or observability.
AI Assurance has a mechanism. It rests on three engineering disciplines that, taken together, make regulatory compliance executable. Not aspirational. Not a manual process. Executable — in your pipeline, on every commit, with audit trails.

Discipline 1: GovOps — Governance as Pipeline Operations
DevOps took operations out of a separate team and embedded it into the development workflow. DevSecOps did the same for security. GovOps does it for governance.
The pattern is the same every time: take a discipline that used to live in a separate department, with its own processes, its own timeline, and its own language — and pull it into the software lifecycle. Make it automated. Make it continuous. Make it fail like a test, not like an audit.
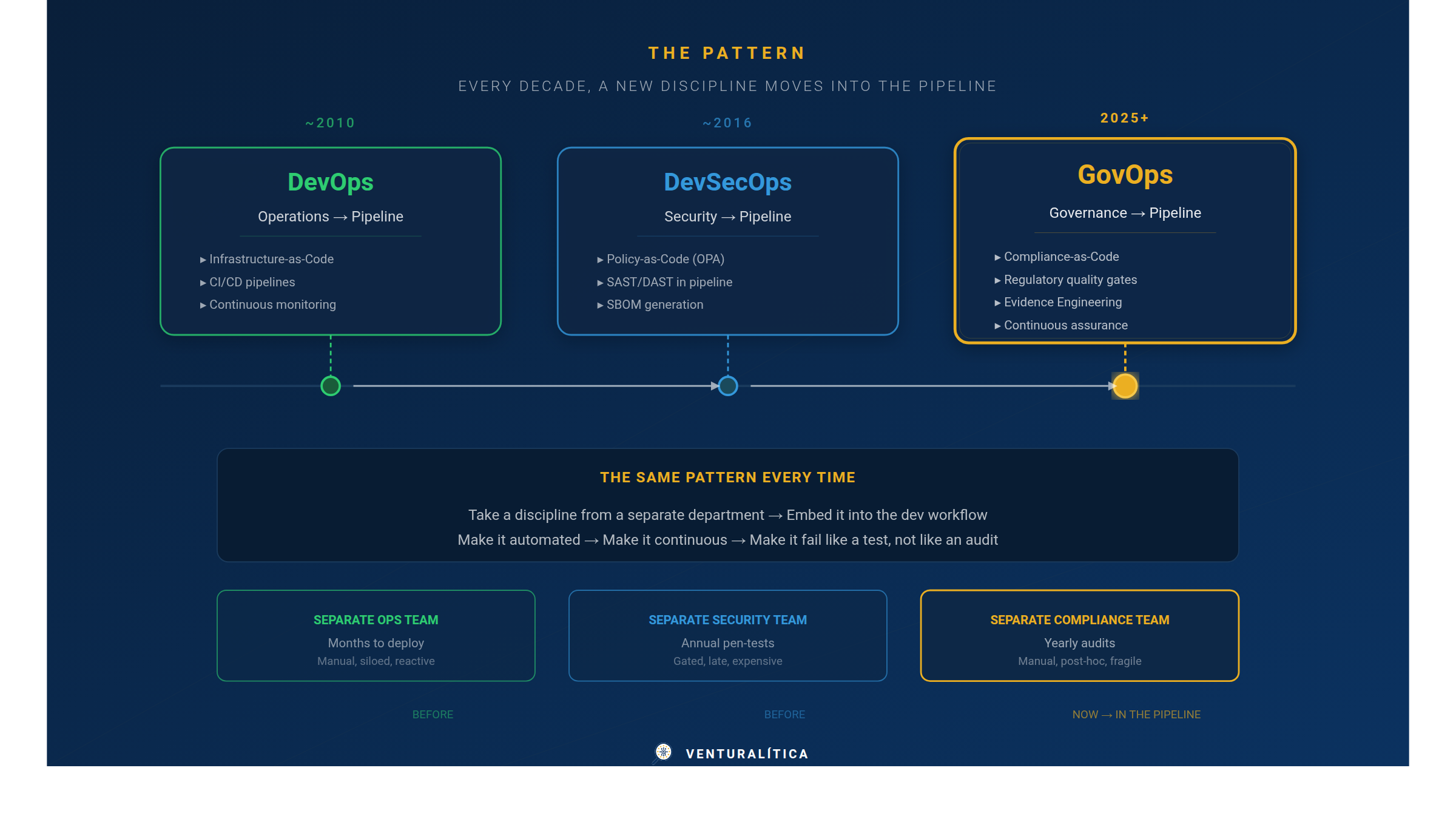
In practice, GovOps means governance checks run in your CI/CD pipeline alongside your linter and your test suite. A model that fails a fairness threshold doesn't deploy — the same way a service that fails a security scan doesn't deploy. The feedback loop is minutes, not months.
Think of it as a new quality gate. You already have gates for tests, coverage, code style, and security vulnerabilities. GovOps adds one more: regulatory compliance. It blocks the merge, not the release calendar.
Think of it as continuous auditing. Instead of reviewing a system once a year and hoping nothing changed, you get a compliance signal on every pipeline execution. When something drifts out of tolerance, you know immediately — not when an auditor finds it.
JFrog coined "DevGovOps" in 2025 for supply chain governance. Harness already implements OPA-based policy gates in deployment pipelines. CML brings CI/CD to the ML lifecycle with GitHub Actions and GitLab CI. The infrastructure exists. What's missing is the regulatory policy layer — the rules that map to specific legal obligations like EU AI Act Articles 9 through 15.
Discipline 2: Compliance-as-Code — Policies You Can Diff
If GovOps is where governance runs (in the pipeline), Compliance-as-Code is what it runs (the rules).
Compliance-as-Code means expressing regulatory requirements as machine-readable, version-controlled policy files that live in your repository alongside your source code. Not a Word document in SharePoint. Not a checklist in a spreadsheet. A structured file that your pipeline can parse, evaluate, and enforce.
The concept isn't new. Open Policy Agent (OPA) has been doing this for infrastructure policies since 2016. Terraform Sentinel enforces cloud governance as code. AWS Config Rules evaluate compliance in real time. The pattern is proven at scale.
What's new is applying it to AI-specific regulations. The EU AI Act mandates risk management (Art. 9), data governance (Art. 10), technical documentation (Art. 11), record-keeping (Art. 12), transparency (Art. 13), human oversight (Art. 14), and accuracy monitoring (Art. 15). Each of these can be codified as a policy with measurable thresholds.
A concrete example: Article 10 requires that training data be "relevant, sufficiently representative, and to the best extent possible, free of errors." Translated to code, that becomes a policy file defining:
- Minimum class balance ratio for the protected attribute: 0.20
- Disparate impact threshold (Four-Fifths Rule): 0.80
- Missing value tolerance per feature: 0.05
These thresholds live in an OSCAL or YAML file, reviewed in pull requests, versioned with your model. When the regulation evolves — or when your risk assessment changes — you update the policy, not a PDF.
It's eslint for compliance. Rules are declarative. You can override them per project. They run automatically. When they fail, you get an actionable message, not a legal opinion.
Every threshold decision is traceable. You can see who set the disparate impact threshold to 0.8, when, and why (the commit message). When a regulator asks "how did you determine this was acceptable?", you have a version history — not a meeting note.
Discipline 3: Evidence Engineering — Proof as a Pipeline Byproduct
GovOps tells you where governance runs. Compliance-as-Code tells you what rules to evaluate. Evidence Engineering answers the hardest question: how do you prove it happened?
The EU AI Act doesn't just require that you manage risk, govern data, and monitor accuracy. It requires that you demonstrate it — with documentation, logs, and records that survive an audit. Article 11 alone (Technical Documentation) references Annex IV, a checklist covering everything from training data provenance to hardware specifications.
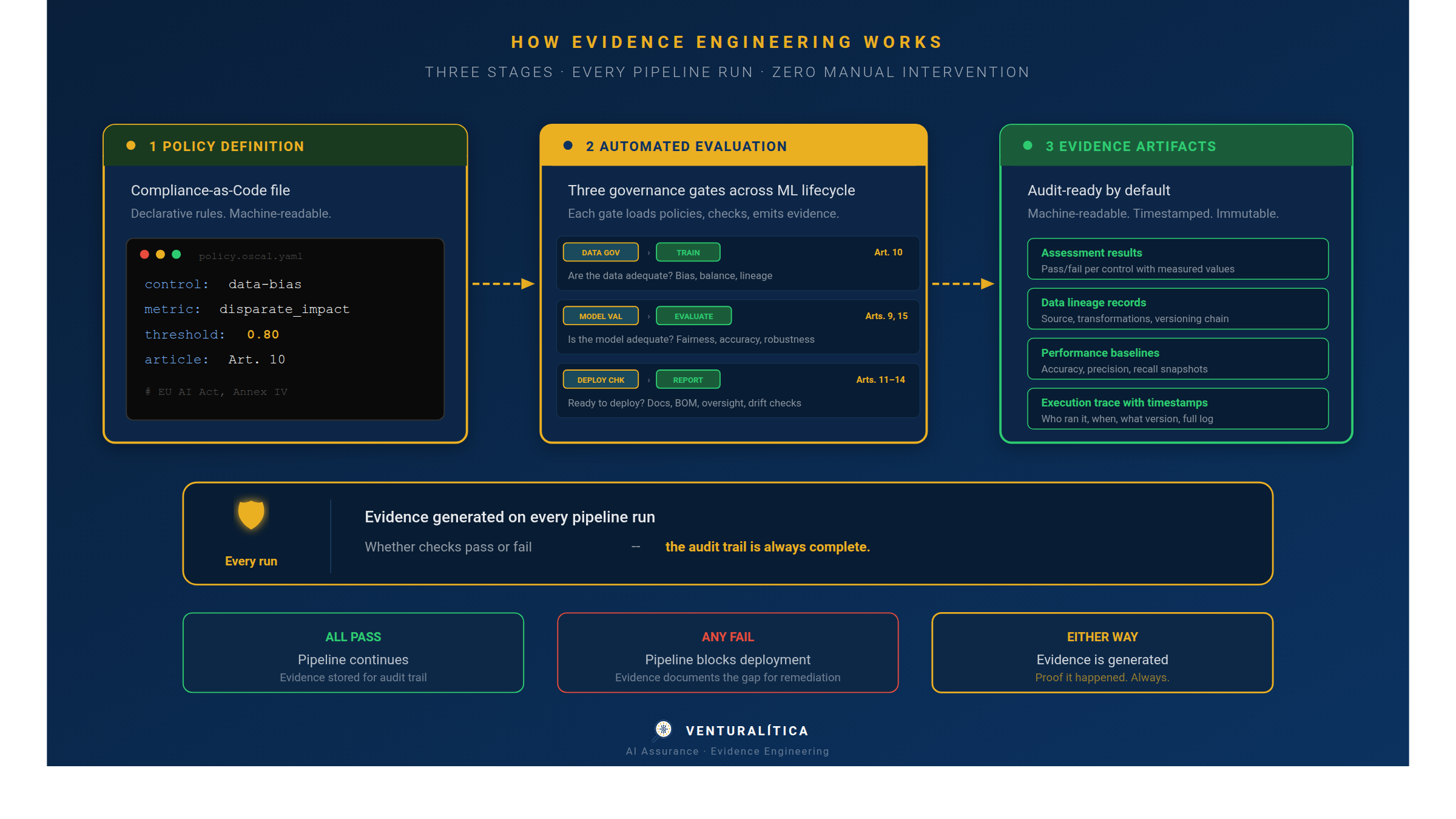
Most organizations treat this as a documentation project: someone writes it up after the fact, often months later, often from memory. Evidence Engineering inverts that model. It generates compliance artifacts automatically, as a byproduct of the pipeline execution.
The principle mirrors observability in distributed systems. You don't write a log summary after an incident — your system emits structured telemetry continuously, and you query it when you need it. Evidence Engineering applies the same logic to regulatory evidence:
- Data lineage records capture where training data came from, how it was transformed, and what quality metrics were measured — addressing Art. 10.
- Software Bills of Materials (CycloneDX ML-BOM) document every dependency, framework version, and hardware fingerprint — addressing Art. 11 and Annex IV.
- Execution traces record code context (function signatures, source hashes), model parameters, and timestamps — addressing Art. 12.
- Integrity checks detect environment drift, dependency changes, and configuration mismatches between training and deployment — addressing Art. 15.
- Performance baselines capture accuracy, fairness, and robustness metrics against held-out test sets — addressing Arts. 9 and 15.

None of this requires manual intervention. The evidence is generated as part of the training or evaluation run, packaged into structured artifacts, and stored with a traceable link to the policy that governed the execution.
It's the audit trail you wish you had the last time someone asked "what version of the model was running on March 12th?" Except it covers compliance dimensions too.
It's the evidence portfolio that takes months to compile manually — generated in seconds, updated on every pipeline run, always current.
The three disciplines together
Each discipline solves one piece. Together, they form a closed loop:
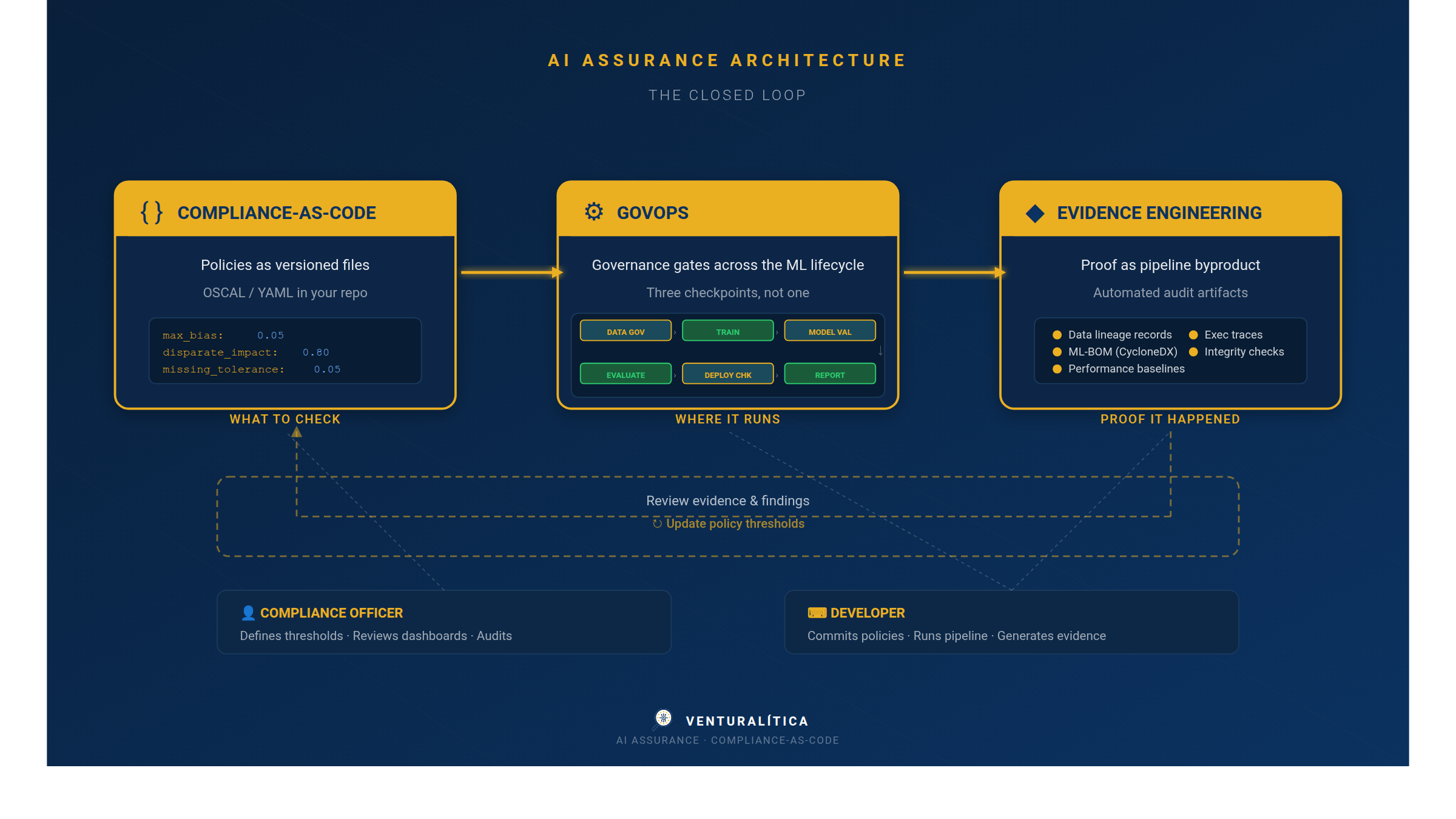
A compliance officer defines the policy: "disparate impact for age must be above 0.5." A developer commits the policy file to the repo. The CI pipeline evaluates it on every training run. If it fails, the pipeline blocks. Whether it passes or fails, the evidence is captured — the measured value, the threshold, the timestamp, the data snapshot, the code version.
Six months later, an auditor asks: "How do you comply with Article 10?" You don't open a Word document. You point to the commit history, the pipeline logs, and the evidence artifacts. Every decision is traceable, every evaluation is reproducible, every threshold change is auditable.
This is what AI Assurance looks like when it's engineered, not consulted.
See it in practice
If you want to experience the loop — policy evaluation, threshold checking, evidence generation — in a single command:
pip install venturalitica
import venturalitica as vl
results = vl.quickstart('loan')
# Evaluates 3 fairness controls on 1,000 real loan applications
# Output: 2 pass, 1 fail (age bias detected: DI = 0.286 vs threshold 0.5)
Six seconds. Policy evaluated. Evidence generated. One line of code between "I assume my data is fair" and "I know it isn't."
The SDK is open source (Apache 2.0). Governance rules are OSCAL-structured, so they're portable to any pipeline — from CML/DVC workflows to GitHub Actions, any framework, any jurisdiction.
GitHub: github.com/venturalitica
AI Assurance is an architecture, not a service
Assessment tells you where you stand. Audit tells you where you fell short. Assurance generates the evidence that makes both useful.
It's not a new bureaucracy. It's three engineering disciplines — GovOps, Compliance-as-Code, and Evidence Engineering — applied to a domain that has been treated as a legal problem for too long.
The infrastructure already exists: CI/CD pipelines, policy engines, structured logging, artifact registries. The regulatory pressure is real: the EU AI Act's technical obligations under Articles 9–15 apply regardless of whether harmonized standards are ready. The only missing piece is connecting them.
That connection is AI Assurance. And it's engineering work.